
🇬🇧 English version avalaible here
GO et chan
J'ai envie d'écrire un article sur les chans en Go car je découvre des tas de bibliothèques qui usent et abusent des chans à tout va, souvent pour des usages qui auraient pu être fait autrement. J'entends également des développeurs évoquer l'usage des chans sans aucune considération de leur implémentation low-level. Par exemple, un développeur annonçait qu'il serait pertinent d'implémenter des objets en go ou chaque objet instancié serait matérialisé par une goroutine, et chaque méthode accessible par un chan.
Go est un langage simple et efficace qui se fixe pour challenge (entre autres) de faciliter la programmation concurrente. Toute personne ayant fait de la programmation concurrente sait que les mécanismes et concepts sous-jacents sont complexes et qu'une mauvaise utilisation peut amener à des situations dramatiques en termes de rapidité d'exécution et de contention. Go propose donc le système de chan pour faciliter la programmation concurrente. Lorsque l'on est habitué à travailler avec des systèmes à base de lock, architecturer un programme Go avec des chan est un exercice déroutant, mais intéressant. Il ne faudra pas longtemps pour s'y habituer et y prendre gout. En revanche, les problèmes de contention sont bien réels, et aucun concept ne facilite leur évitement.
Il y a quelque temps, j'ai rencontré un problème de ce type sur InfluxDB. Ce problème illustre parfaitement le type de comportement que l'on peut rencontrer avec un programme écrit en Go. J'ai été face à de gros problèmes de performances, de consommation CPU et de consommation mémoire lorsque le programme fonctionne avec un seul avec un seul CPU. Il suffira de passer à 4 CPU pour que le problème disparaisse ![]() 100% cpu consummatiun from 2.07 to 2.0.8. De prime abord cela peut paraitre naturel que les problèmes de CPU disparaissent en ajoutant de la CPU, mais le facteur d'augmentation des CPU est de x4, alors que le gain en performances est de ~ x10. Par ailleurs ce comportement apparait suite à une montée de version.
100% cpu consummatiun from 2.07 to 2.0.8. De prime abord cela peut paraitre naturel que les problèmes de CPU disparaissent en ajoutant de la CPU, mais le facteur d'augmentation des CPU est de x4, alors que le gain en performances est de ~ x10. Par ailleurs ce comportement apparait suite à une montée de version.
Que sont les chans ?
Les chans se présentent comme un canal de communication. Une ou plusieurs goroutines mettent des données dans un chan et une ou plusieurs goroutines consomment ces données. Le chan incitera à dupliquer l'information en mémoire à chaque envoi de données, ce qui évitera les problèmes de mémoire partagée. Les chans sont donc un mécanisme particulièrement agréable à utiliser car ils ont tendance à matérialiser une action de communication, là ou un programme à base de lock ne montre que du partage de mémoire. Cette manière de modéliser une problématique avec des chans comme un canal de communication est d'un tel confort qu'elle peut rapidement faire oublier au développeur le système sous-jacent.
La baseline de Go relative aux chans est :
Do not communicate by sharing memory; instead, share memory by communicating.
Cette baseline n'est que partiellement vrai. Le partage de mémoire par la communication n'est qu'une propriété émergente du système. Le concept de canal de communication n'existe pas au cœur d'un microprocesseur. En effet, les chans ne sont qu'une abstraction de la réalité et sont implémentés par un algorithme à base de listes et de lock. Leur usage n'est pas sans conséquences, et les chans apportent les mêmes problématiques que la programmation concurrente traditionnelle.
Qu'est-ce qu'un lock et quels sont ces impacts ?
Afin de comprendre pourquoi les chans amènent des problèmes de lenteur aux programmes, il faut comprendre comment fonctionne un lock. De manière simplifiée, un lock est un bit positionné en mémoire. La règle est que seul le processus ayant positionné ce bit peut l'enlever, tous les autres processus restent en attente tant que ce bit est vrai.
L'explication qui suit est un peu simplifiée, mais cela n'impacte pas le raisonnement (Je n'aborde pas le détail des différents niveaux de cache, du concept de thread au cœur d'un core, et simplifie le lock de bus mémoire). Chaque core d'un système aura des ressources partagées avec ses homologues. La ressource partagée qui nous intéresse est la mémoire. Un système simplifié est composé de mémoire RAM et de processeurs, un processeur est composé de mémoire cache et de cores.

Un core va disposer d'une mémoire cache L1 exclusivement dédiée, c'est une mémoire qui fonctionne à une vitesse proche de celle du core, aussi une écriture dans cette mémoire sera très rapide et aura peu d'impact sur la vitesse d'exécution du programme.
Un processeur va contenir plusieurs cores ainsi qu'un second cache mémoire L2 plus lent que le précédent commun à tous ces cores. Pour que le second core ait accès aux données écrites par le premier en mémoire, les données doivent remonter dans ce second cache.
Un système est composé de plusieurs processeurs et de RAM commune à tous ces processeurs. La RAM est très lente par rapport aux caches L1 & L2. Pour qu'un core d'un second processeur ait accès aux données écrites en mémoire par un core d'un premier processeur, ces données doivent être dans la RAM.
L'ordre de grandeur des vitesses d'accès au différent niveau de mémoire est le suivant :
- Cache L1 (proche du core) : environ 1 à 2 nanosecondes
- Cache L2 : environ 3 à 10 nanosecondes
- Cache L3 : environ 10 à 20 nanosecondes
- RAM : environ 60 à 100 nanosecondes
Nous avons vu que pour que tous les cores aient le même niveau d'information, il faut que l'information soit présente dans la RAM et que la RAM est très lente. Aussi chaque opération relative à un lock va nécessiter un accès à la RAM, or la RAM est 30 à 100 fois plus lente que le cache L1, ce qui marque une pause dans l'exécution du programme. Plus le programme va faire de lock, plus il sera lent.
Qu'est-ce qu'une goroutine ?
Les goroutine sont des unités d'exécution légères. Contrairement aux threads, elles n'ont pas de réalité au niveau du systèmes et n'existent qu'en userland. Au démarrage Go va démarrer un certain nombre de threads systèmes, et va faire appel à son ordonnanceur pour gérer l'exécution des goroutines au sein de ces threads.
Le langage Go impose la programmation bloquante. C'est-à-dire que des actions peuvent imposer une pause à l'exécution en attendant une réponse. Parmi ces actions, on trouve les appel système (accès réseau, accès aux fichiers, …), le délai d'attente, mais aussi les locks et les I/O dans des chans.
Sans entrer dans le détail du fonctionnement, le compilateur crée un ordonnanceur basé sur une run-queue. La run-queue est une liste qui contient toutes les go routines qui doivent être exécutés. Chaque fois qu'une goroutine atteint un point bloquant, son exécution est stoppée et l'ordonnanceur va exécuter une autre goroutine présente dans la run-queue. Notons que l'ordonnanceur Go dispose d'optimisations qui permettent d'éviter les locks lorsque les interlocuteurs d'une communication via des chan sont sur un même thread.
Notons donc que :
-N'importe quel thread peu exécuter n'importe quelle goroutine. -Une même goroutine peut passer de thread en thread au long de sa vie. -Une goroutine qui écrit dans un chan pourra avoir la gouroutine en charge de la lecture du chan exécuté dans le même thread. -Il y une optimisation si les échanges entre goroutines sont sur un même thread.
De l'usage des chans
De base, Go garanti une écriture et une lecture dans un chan. L'écriture ne peut pas échouer, aussi une goroutine sera bloqué tant que l'écriture ne sera pas effective ou le chan fermé. De la même manière, lors de la lecture d'un chan, la goroutine sera bloquée tant qu'elle n'aura pas lu une donnée ou que le chan sera fermé. Si un chan est alimenté par plusieurs producteurs de données, il se peut que les producteurs se gênent entre eux pour écrire.
Après avoir désassemblé un bout de code Go qui utilise des chans, on voit clairement que l'implémentation des chans s'appuie sur le système classique à base de lock fourni par le runtime Go.
J'écris un exemple pour mettre clairement en avant la contention : j'ai une goroutine qui produit une chaine de 300 caractères random, et 3 goroutines qui les consomment en faisant 5 calculs sha1 des données reçues. Le but est d'avoir un consommateur qui met plus de temps à traiter la donnée que le producteur à la produire, ce qui justifie l'usage de plusieurs processeurs.
package main
import "crypto/sha1"
import "hash"
import "math/rand"
const log_len = 300
const chan_size = 25
const goroutine_nb = 3
const batch_sz = 1000
func main() {
//test_producer()
//test_worker()
produce()
//produce_batch()
}
/* perform 5 sha1 hash */
func consumer(parse string)(bool) {
var h hash.Hash
var i int
for i = 0; i < 5; i++ {
h = sha1.New()
h.Write([]byte(parse))
_ = h.Sum(nil)
}
return true
}
/* Generate 300 bytes of ascii text */
func producer()(string) {
var err error
var buf [log_len]byte
var i int
/* read random data */
_, err = rand.Read(buf[:])
if err != nil {
panic(err)
}
/* convert to ascii and remove controls */
for i = 0; i < len(buf); i++ {
buf[i] = buf[i] & 0x7f
if buf[i] < 0x20 || buf[i] == 0x7f {
buf[i] = 0x20
}
}
return string(buf[:])
}
/* Produce 10M lines */
func test_producer() {
var i int
for i = 0; i < 10000000; i++ {
producer()
}
}
/* test consumer using 10M lines */
func test_worker() {
var i int
var s string = producer()
for i = 0; i < 10000000; i++ {
consumer(s)
}
}
func consume(chan_string chan string) {
for {
consumer(<-chan_string)
}
}
func produce() {
var i int
var chan_string chan string = make(chan string, chan_size)
for i = 0; i < goroutine_nb; i++ {
go consume(chan_string)
}
for i = 0; i < 10000000; i++ {
chan_string <- producer()
}
}
func consume_batch(chan_string chan []string) {
var s []string
var one_s string
for {
s = <-chan_string
for _, one_s = range s {
consumer(one_s)
}
}
}
func produce_batch() {
var i int
var j int
var s []string
var chan_string chan []string = make(chan []string, chan_size)
for i = 0; i < goroutine_nb; i++ {
go consume_batch(chan_string)
}
for i = 0; i < 10000000 / batch_sz; i++ {
s = make([]string, batch_sz)
for j = 0; j < batch_sz; j++ {
s[j] = producer()
}
chan_string <- s
}
}
Les références de temps sont liées à mon CPU, si vous testez le code chez vous, le temps ne sera pas le même, mais l'ordre de grandeur devrait être respecté.
Tout d'abord testons le producteur. L'ordonnanceur Go va fonctionner avec plusieurs threads, aussi dans le but de savoir ce que peut produire un seul core, l'exécution du programme est contrainte sur un seul thread et un seul CPU avec cette commande :
time GOMAXPROCS=1 taskset 0x1 ./test
Il produit 10M de lignes en ~15s, soit ~667k lignes par seconde. Testons le consommateur dans les mêmes conditions que le producteur. Il analyse 10M de lignes en 35s, soit ~286k lignes par seconde. Il faut donc 2,33 consommateurs pour traiter la charge d'un producteur.
Testons l'effet du chan. Le producteur met ses strings dans un chan d'une taille que l'on ferra varier, et un nombre variable de consommateurs prennent leurs données dans ce chan. Vu le benchmark unitaire, 4 CPU suffisent pour que les consommateurs traitent tout ce qui est envoyés par le producteur, et le traitement devrait s'effectuer en ~15s.

Je démarre 1 producteur et 3 consommateurs. On s'attend donc à avoir 3 cores saturés et une consommation de 33% sur le 4ème core, ou une consommation moyenne sur les 4 cores de 83%.
Le constat est que chacun des 4 CPU travaille à 41% de sa capacité et qu'il faut 50s pour traiter les 10M de lignes de logs. On est loin de l'objectif de ~15s et 83% de consommation CPU. Avec cette architecture qui suit l'intuition, on obtient de la contention, et on ne peut pas tirer le meilleur parti du matériel que l'on utilise.

Faisons varier la taille du chan de distribution des jobs pour voir si ce paramètre influe sur les performances. Voilà le résultat ou je mets en relation la consommation CPU avec la taille du chan :
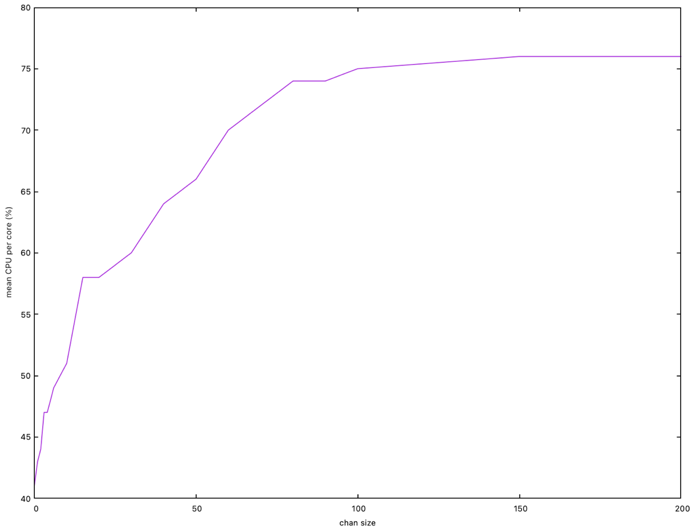
On atteint un temps minimal de traitement de ~26s à partir de 100 slots. Notons donc que la taille du chan influx directement sur les performances. Le temps minimal théorique de ~15s n'est pas atteint, la consommation CPU théorique moyenne de 83% n'est pas non plus atteinte.
La performance s'améliore en augmentant la taille du chan, car l'optimisation liée à l'ordonnanceur Go, fait que les locks sont utilisés moins souvent car plus de données sont produites sans lock et les consommateurs se gênent moins entre eux.
Faisons varier le nombre de goroutines qui consomment les données. Le graphe ci-dessous montre la relation entre la consommation CPU avec le nombre de consommateurs.
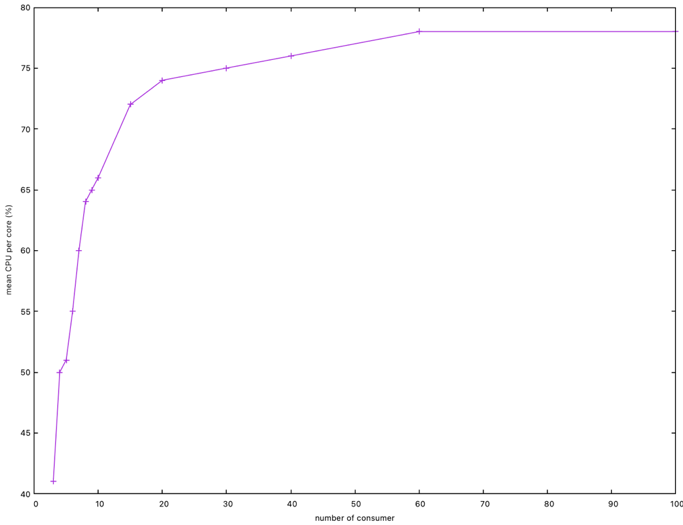
Il faut approximativement 60 goroutines pour atteindre un temps minimum de ~26s et une consommation CPU moyenne de 78%. Encore une fois, le temps optimal n'est pas attteint.
De la même manière qu'en augmentant la taille du chan, l'augmentation du nombre de goroutines fait que plusieurs consommateurs s'exécutent sur les mêmes threads, et les optimisations de l'ordonnanceur Go font que moins de lock sont utilisés.
Comment travailler efficacement avec les chans ?
Le simple usage de chan créera de la contention quelle que soit la manière dont ils sont utilisés. Les performances théoriques ne seront pas atteintes. Ceci est vrai pour tous les langages et méthodes de programmation concurrente. C'est intrinsèquement lié aux points de synchronisation entre process. Pendant que le CPU attend une donnée (un lock) en RAM (et non en cache) il ne fait rien et ne peut rien faire d'autre. Est-ce que votre programme nécessite vraiment l'usage de programmation concurrente et de plusieurs CPU ? Si ce n'est pas le cas, fixer GOMAXPROC à 1 (![]() func GOMAXPROCS) avec la réduction au strict nécessaire de l'usage des chans, peut assurer le plein potentiel de l'ordonnancer Go sur un CPU.
func GOMAXPROCS) avec la réduction au strict nécessaire de l'usage des chans, peut assurer le plein potentiel de l'ordonnancer Go sur un CPU.
Si vous développez un programme qui n'a de besoin de performances ou de temps de traitement faibles, alors privilégiez la lisibilité du code à son optimisation. Cela dit, si le programme évolue et nécessite des performances, il sera peut-être nécessaire de revoir son architecture.
Éviter l'usage abusif des chans. Les chans grèvent le fonctionnement du programme lorsqu'ils sont utilisés à haute fréquence pour faire de très petites tâches. Voilà quelques manières de contourner ce problème :
Pour éviter l'abus des chans passez par une phase de réflexion et d'architecture avant de coder. Le but est d'identifier au mieux les besoins en parallélisations pour les limiter au maximum. Il est également indispensable d'identifier les goroutines qui seront solliciter très souvent pour une charge de travail très faible. Au passage, vous pouvez tracer un graphe des communications entre goroutines afin d'éviter les dead-locks.
Identifiez et qualifiez les bibliothèques que vous embarquez dans votre programme. Go a pour avantage d'être très fourni en contributions, mais cela apporte un lot de code de mauvaise qualité. Il est nécessaire d'identifier ces bibliothèques et de ne pas les utiliser.
Si la tâche est vraiment peu consommatrice en termes de CPU, pourquoi la mettre dans une goroutine dédiée et pas directement au cœur du code ? Privilégiez des goroutines qui ont une assez grande quantité de code à exécuter.
Il est peut-être acceptable de faire grossir artificiellement la tâche exécutée par la goroutine en lui donnant une liste de données plutôt qu'une donnée simple ? Ce grossissement ferra baisser la fréquence d'appel des chans. Dans le code d'exemple, j'arrive à atteindre le temps minimum de ~23s en faisant des batch de traitement de 1000 strings.
Réglez les tailles des chan critiques. Je ne connais aucune méthode pour trouver une valeur optimale par le calcul, l'expérimentation sera probablement la solution. Mettez donc un maximum de métriques dans votre programme, il peut être de bon ton de mesurer le remplissage de certains chans, le nombre d'événements traités par seconde, ou tout autre indicateur pertinent. Par ailleurs, il sera très pratique de rendre les taille de chans et les nombre de worker configurables.