
🇫🇷 Version française disponible ici
GO and chan
I want to write an article on chans in Go because I'm discovering many libraries that use and abuse chans left and right, often for uses that could have been done differently. I also hear developers discussing the use of chans without any consideration of their low-level implementation. For example, a developer announced that it would be relevant to implement objects in go where each instantiated object would be materialized by a goroutine, and each method accessible through a chan.
Go is a simple and efficient language that sets itself the challenge (among others) of facilitating concurrent programming. Anyone who has done concurrent programming knows that the underlying mechanisms and concepts are complex and that misuse can lead to dramatic situations in terms of execution speed and contention. Go therefore proposes the chan system to facilitate concurrent programming. When you're used to working with lock-based systems, architecting a Go program with chans is a confusing but interesting exercise. It won't take long to get used to it and develop a taste for it. However, contention problems are very real, and no concept facilitates their avoidance.
Some time ago, I encountered a problem of this type on InfluxDB. This problem perfectly illustrates the type of behavior you can encounter with a program written in Go. I faced major performance problems, CPU consumption and memory consumption when the program runs with a single CPU. It was enough to switch to 4 CPUs for the problem to disappear ![]() 100% cpu consumption from 2.07 to 2.0.8. At first glance this may seem natural that CPU problems disappear by adding CPU, but the CPU increase factor is x4, while the performance gain is ~ x10. Furthermore, this behavior appears following a version upgrade.
100% cpu consumption from 2.07 to 2.0.8. At first glance this may seem natural that CPU problems disappear by adding CPU, but the CPU increase factor is x4, while the performance gain is ~ x10. Furthermore, this behavior appears following a version upgrade.
What are chans?
Chans present themselves as a communication channel. One or more goroutines put data into a chan and one or more goroutines consume this data. The chan will encourage duplicating information in memory at each data send, which will avoid shared memory problems. Chans are therefore a particularly pleasant mechanism to use because they tend to materialize a communication action, where a lock-based program only shows memory sharing. This way of modeling a problem with chans as a communication channel is so comfortable that it can quickly make the developer forget the underlying system.
Go's baseline relative to chans is:
Do not communicate by sharing memory; instead, share memory by communicating.
This baseline is only partially true. Memory sharing through communication is only an emergent property of the system. The concept of communication channel does not exist at the heart of a microprocessor. Indeed, chans are only an abstraction of reality and are implemented by an algorithm based on lists and locks. Their use is not without consequences, and chans bring the same problems as traditional concurrent programming.
What is a lock and what are its impacts?
In order to understand why chans bring slowness problems to programs, you need to understand how a lock works. In a simplified way, a lock is a bit positioned in memory. The rule is that only the process that positioned this bit can remove it, all other processes remain waiting as long as this bit is true.
The following explanation is somewhat simplified, but this doesn't impact the reasoning (I don't address the detail of different cache levels, the concept of thread at the heart of a core, and simplify the memory bus lock). Each core of a system will have shared resources with its counterparts. The shared resource that interests us is memory. A simplified system is composed of RAM memory and processors, a processor is composed of cache memory and cores.

A core will have an exclusively dedicated L1 cache memory, it's a memory that operates at a speed close to that of the core, so a write to this memory will be very fast and will have little impact on the program's execution speed.
A processor will contain several cores as well as a second L2 memory cache slower than the previous one common to all these cores. For the second core to have access to data written by the first in memory, the data must rise to this second cache.
A system is composed of several processors and RAM common to all these processors. RAM is very slow compared to L1 & L2 caches. For a core of a second processor to have access to data written in memory by a core of a first processor, this data must be in RAM.
The order of magnitude of access speeds to different memory levels is as follows:
- L1 Cache (close to core): about 1 to 2 nanoseconds
- L2 Cache: about 3 to 10 nanoseconds
- L3 Cache: about 10 to 20 nanoseconds
- RAM: about 60 to 100 nanoseconds
We have seen that for all cores to have the same level of information, the information must be present in RAM and that RAM is very slow. So each operation relative to a lock will require access to RAM, but RAM is 30 to 100 times slower than L1 cache, which marks a pause in the program's execution. The more locks the program makes, the slower it will be.
What is a goroutine?
Goroutines are lightweight execution units. Unlike threads, they have no reality at the system level and exist only in userland. At startup Go will start a certain number of system threads, and will call on its scheduler to manage the execution of goroutines within these threads.
The Go language imposes blocking programming. That is to say that actions can impose a pause in execution while waiting for a response. Among these actions, we find system calls (network access, file access, ...), waiting delay, but also locks and I/O in chans.
Without going into the detail of operation, the compiler creates a scheduler based on a run-queue. The run-queue is a list that contains all the go routines that must be executed. Each time a goroutine reaches a blocking point, its execution is stopped and the scheduler will execute another goroutine present in the run-queue. Note that the Go scheduler has optimizations that avoid locks when the participants in a communication via chans are on the same thread.
Note therefore that:
- Any thread can execute any goroutine.
- The same goroutine can pass from thread to thread throughout its life.
- A goroutine that writes to a chan may have the goroutine in charge of reading the chan executed in the same thread.
- There is an optimization if exchanges between goroutines are on the same thread.
On the use of chans
By default, Go guarantees a write and a read in a chan. The write cannot fail, so a goroutine will be blocked as long as the write is not effective or the chan closed. In the same way, when reading a chan, the goroutine will be blocked as long as it has not read data or the chan is closed. If a chan is fed by several data producers, it may be that the producers interfere with each other to write.
After having disassembled a piece of Go code that uses chans, we clearly see that the implementation of chans relies on the classic lock-based system provided by the Go runtime.
I write an example to clearly highlight contention: I have a goroutine that produces a string of 300 random characters, and 3 goroutines that consume them by doing 5 sha1 calculations of the received data. The goal is to have a consumer that takes more time to process the data than the producer to produce it, which justifies the use of several processors.
package main
import "crypto/sha1"
import "hash"
import "math/rand"
const log_len = 300
const chan_size = 25
const goroutine_nb = 3
const batch_sz = 1000
func main() {
//test_producer()
//test_worker()
produce()
//produce_batch()
}
/* perform 5 sha1 hash */
func consumer(parse string)(bool) {
var h hash.Hash
var i int
for i = 0; i < 5; i++ {
h = sha1.New()
h.Write([]byte(parse))
_ = h.Sum(nil)
}
return true
}
/* Generate 300 bytes of ascii text */
func producer()(string) {
var err error
var buf [log_len]byte
var i int
/* read random data */
_, err = rand.Read(buf[:])
if err != nil {
panic(err)
}
/* convert to ascii and remove controls */
for i = 0; i < len(buf); i++ {
buf[i] = buf[i] & 0x7f
if buf[i] < 0x20 || buf[i] == 0x7f {
buf[i] = 0x20
}
}
return string(buf[:])
}
/* Produce 10M lines */
func test_producer() {
var i int
for i = 0; i < 10000000; i++ {
producer()
}
}
/* test consumer using 10M lines */
func test_worker() {
var i int
var s string = producer()
for i = 0; i < 10000000; i++ {
consumer(s)
}
}
func consume(chan_string chan string) {
for {
consumer(<-chan_string)
}
}
func produce() {
var i int
var chan_string chan string = make(chan string, chan_size)
for i = 0; i < goroutine_nb; i++ {
go consume(chan_string)
}
for i = 0; i < 10000000; i++ {
chan_string <- producer()
}
}
func consume_batch(chan_string chan []string) {
var s []string
var one_s string
for {
s = <-chan_string
for _, one_s = range s {
consumer(one_s)
}
}
}
func produce_batch() {
var i int
var j int
var s []string
var chan_string chan []string = make(chan []string, chan_size)
for i = 0; i < goroutine_nb; i++ {
go consume_batch(chan_string)
}
for i = 0; i < 10000000 / batch_sz; i++ {
s = make([]string, batch_sz)
for j = 0; j < batch_sz; j++ {
s[j] = producer()
}
chan_string <- s
}
}
The time references are linked to my CPU, if you test the code at your place, the time will not be the same, but the order of magnitude should be respected.
First let's test the producer. The Go scheduler will work with several threads, so in order to know what a single core can produce, the program execution is constrained on a single thread and a single CPU with this command:
time GOMAXPROCS=1 taskset 0x1 ./test
It produces 10M lines in ~15s, which is ~667k lines per second. Let's test the consumer under the same conditions as the producer. It analyzes 10M lines in 35s, which is ~286k lines per second. It therefore takes 2.33 consumers to process the load of one producer.
Let's test the effect of the chan. The producer puts its strings in a chan of a size that we will vary, and a variable number of consumers take their data from this chan. Given the unit benchmark, 4 CPUs are sufficient for consumers to process everything that is sent by the producer, and processing should be done in ~15s.

I start 1 producer and 3 consumers. We therefore expect to have 3 saturated cores and 33% consumption on the 4th core, or an average consumption on the 4 cores of 83%.
The observation is that each of the 4 CPUs works at 41% of its capacity and that it takes 50s to process the 10M lines of logs. We are far from the objective of ~15s and 83% CPU consumption. With this architecture that follows intuition, we get contention, and we cannot make the best use of the hardware we use.

Let's vary the size of the job distribution chan to see if this parameter influences performance. Here is the result where I relate CPU consumption with chan size:
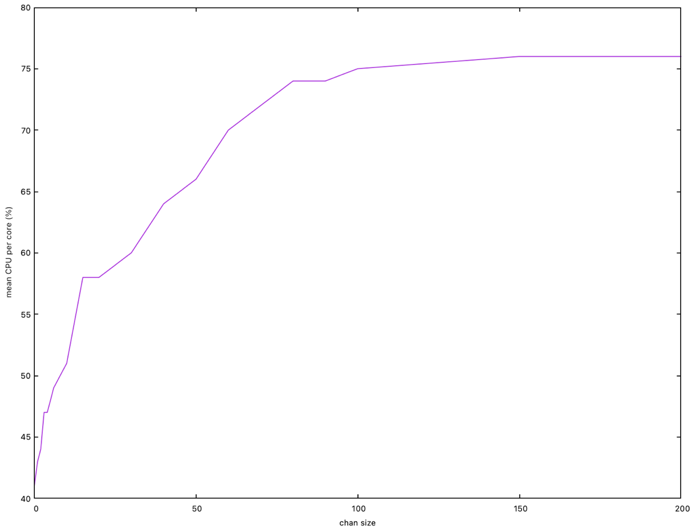
We reach a minimum processing time of ~26s from 100 slots. Note therefore that chan size directly influences performance. The theoretical minimum time of ~15s is not reached, the theoretical average CPU consumption of 83% is not reached either.
Performance improves by increasing chan size, because the optimization linked to the Go scheduler, makes locks are used less often because more data is produced without lock and consumers interfere less with each other.
Let's vary the number of goroutines that consume the data. The graph below shows the relationship between CPU consumption with the number of consumers.
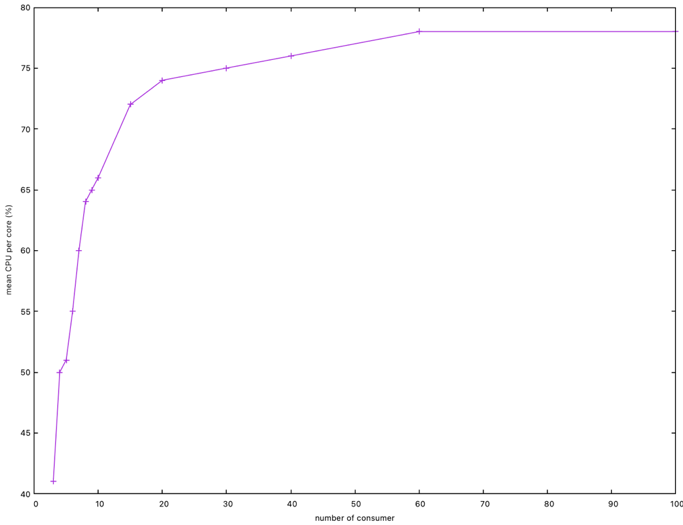
It takes approximately 60 goroutines to reach a minimum time of ~26s and an average CPU consumption of 78%. Once again, the optimal time is not reached.
In the same way as increasing chan size, increasing the number of goroutines means that several consumers execute on the same threads, and the Go scheduler optimizations mean that fewer locks are used.
How to work efficiently with chans?
The simple use of chan will create contention regardless of the way they are used. Theoretical performance will not be achieved. This is true for all languages and concurrent programming methods. It is intrinsically linked to synchronization points between processes. While the CPU waits for data (a lock) in RAM (and not in cache) it does nothing and can do nothing else. Does your program really require the use of concurrent programming and several CPUs? If not, setting GOMAXPROC to 1 (![]() func GOMAXPROCS) with the reduction to the strict necessary of chan usage, can ensure the full potential of the Go scheduler on one CPU.
func GOMAXPROCS) with the reduction to the strict necessary of chan usage, can ensure the full potential of the Go scheduler on one CPU.
If you develop a program that doesn't need performance or low processing time, then prioritize code readability over its optimization. That said, if the program evolves and requires performance, it may be necessary to review its architecture.
Avoid abusive use of chans. Chans burden the program's operation when they are used at high frequency to do very small tasks. Here are some ways to work around this problem:
To avoid chan abuse go through a reflection and architecture phase before coding. The goal is to identify as well as possible the parallelization needs to limit them to the maximum. It is also essential to identify goroutines that will be solicited very often for a very low workload. In passing, you can draw a graph of communications between goroutines in order to avoid dead-locks.
Identify and qualify the libraries you embed in your program. Go has the advantage of being very well supplied with contributions, but this brings a lot of poor quality code. It is necessary to identify these libraries and not use them.
If the task is really not CPU-consuming, why put it in a dedicated goroutine and not directly at the heart of the code? Favor goroutines that have a fairly large amount of code to execute.
It may be acceptable to artificially grow the task executed by the goroutine by giving it a list of data rather than simple data? This growth will lower the frequency of chan calls. In the example code, I manage to reach the minimum time of ~23s by doing batches of processing 1000 strings.
Adjust the sizes of critical chans. I don't know any method to find an optimal value by calculation, experimentation will probably be the solution. So put a maximum of metrics in your program, it can be good practice to measure the filling of certain chans, the number of events processed per second, or any other relevant indicator. Furthermore, it will be very practical to make the chan sizes and number of workers configurable.